Word embeddings are widely used now in many text applications or natural language processing moddels. In the previous posts I showed examples how to use word embeddings from word2vec Google, glove models for different tasks including machine learning clustering:
GloVe – How to Convert Word to Vector with GloVe and Python
word2vec – Vector Representation of Text – Word Embeddings with word2vec
word2vec application – K Means Clustering Example with Word2Vec in Data Mining or Machine Learning
In this post we will look at fastText word embeddings in machine learning. You will learn how to load pretrained fastText, get text embeddings and do text classification. As stated on fastText site – text classification is a core problem to many applications, like spam detection, sentiment analysis or smart replies. [1]
What is fastText
fastText is an open-source, free, lightweight library that allows users to learn text representations and text classifiers. [1]
fastText, is created by Facebook’s AI Research (FAIR) lab. The model is an unsupervised learning algorithm for obtaining vector representations for words. Facebook makes available pretrained models for 294 languages.[2]
As per Quora [6], Fasttext treats each word as composed of character ngrams. So the vector for a word is made of the sum of this character n grams. Word2vec (and glove) treat words as the smallest unit to train on. This means that fastText can generate better word embeddings for rare words. Also fastText can generate word embeddings for out of vocabulary word but word2vec and glove can not do this.
Word Embeddings File
I downloaded wiki file wiki-news-300d-1M.vec from here [4], but there are some other links where you can download different data files. I found this one has smaller size so it is easy to work with it.
Basic Operations with fastText Word Embeddings
To get most similar words to some word:
from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format('wiki-news-300d-1M.vec')
print (model.most_similar('desk'))
"""
[('desks', 0.7923153638839722), ('Desk', 0.6869951486587524), ('desk.', 0.6602819561958313), ('desk-', 0.6187258958816528), ('credenza', 0.5955315828323364), ('roll-top', 0.5875717401504517), ('rolltop', 0.5837830305099487), ('bookshelf', 0.5758029222488403), ('Desks', 0.5755287408828735), ('sofa', 0.5617446899414062)]
"""
Load words in vocabulary:
words = []
for word in model.vocab:
words.append(word)
To see embeddings:
print("Vector components of a word: {}".format(
model[words[0]]
))
"""
Vector components of a word: [-0.0451 0.0052 0.0776 -0.028 0.0289 0.0449 0.0117 -0.0333 0.1055
.......................................
-0.1368 -0.0058 -0.0713]
"""
The Problem
So here we will use fastText word embeddings for text classification of sentences. For this classification we will use sklean Multi-layer Perceptron classifier (MLP).
The sentences are prepared and inserted into script:
sentences = [['this', 'is', 'the', 'good', 'machine', 'learning', 'book'],
['this', 'is', 'another', 'machine', 'learning', 'book'],
['one', 'more', 'new', 'book'],
['this', 'is', 'about', 'machine', 'learning', 'post'],
['orange', 'juice', 'is', 'the', 'liquid', 'extract', 'of', 'fruit'],
['orange', 'juice', 'comes', 'in', 'several', 'different', 'varieties'],
['this', 'is', 'the', 'last', 'machine', 'learning', 'book'],
['orange', 'juice', 'comes', 'in', 'several', 'different', 'packages'],
['orange', 'juice', 'is', 'liquid', 'extract', 'from', 'fruit', 'on', 'orange', 'tree']]
The sentences belong to two classes, the labels for classes will be assigned later as 0,1. So our problem is to classify above sentences. Below is the flowchart of the program that we will use for perceptron learning algorithm example.
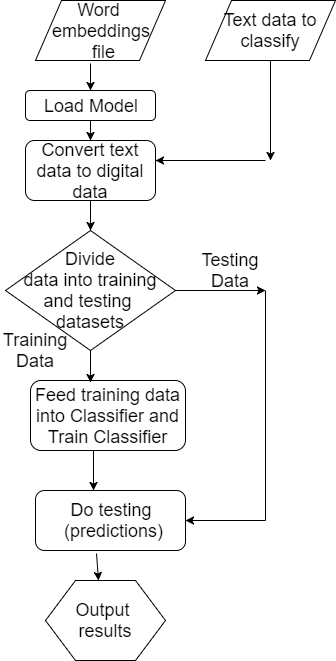
Data Preparation
I converted this text input into digital using the following code. Basically I got word embedidings and averaged all words in the sentences. The resulting vector sentence representations were saved to array V.
import numpy as np
def sent_vectorizer(sent, model):
sent_vec =[]
numw = 0
for w in sent:
try:
if numw == 0:
sent_vec = model[w]
else:
sent_vec = np.add(sent_vec, model[w])
numw+=1
except:
pass
return np.asarray(sent_vec) / numw
V=[]
for sentence in sentences:
V.append(sent_vectorizer(sentence, model))
After converting text into vectors we can divide data into training and testing datasets and attach class labels.
X_train = V[0:6]
X_test = V[6:9]
Y_train = [0, 0, 0, 0, 1,1]
Y_test = [0,1,1]
Text Classification
Now it is time to load data to MLP Classifier to do text classification.
from sklearn.neural_network import MLPClassifier
classifier = MLPClassifier(alpha = 0.7, max_iter=400)
classifier.fit(X_train, Y_train)
df_results = pd.DataFrame(data=np.zeros(shape=(1,3)), columns = ['classifier', 'train_score', 'test_score'] )
train_score = classifier.score(X_train, Y_train)
test_score = classifier.score(X_test, Y_test)
print (classifier.predict_proba(X_test))
print (classifier.predict(X_test))
df_results.loc[1,'classifier'] = "MLP"
df_results.loc[1,'train_score'] = train_score
df_results.loc[1,'test_score'] = test_score
print(df_results)
"""
Output
classifier train_score test_score
MLP 1.0 1.0
"""
In this post we learned how to use pretrained fastText word embeddings for converting text data into vector model. We also looked how to load word embeddings into machine learning algorithm. And in the end of post we looked at machine learning text classification using MLP Classifier with our fastText word embeddings. You can find full python source code and references below.
from gensim.models import KeyedVectors
import pandas as pd
model = KeyedVectors.load_word2vec_format('wiki-news-300d-1M.vec')
print (model.most_similar('desk'))
words = []
for word in model.vocab:
words.append(word)
print("Vector components of a word: {}".format(
model[words[0]]
))
sentences = [['this', 'is', 'the', 'good', 'machine', 'learning', 'book'],
['this', 'is', 'another', 'machine', 'learning', 'book'],
['one', 'more', 'new', 'book'],
['this', 'is', 'about', 'machine', 'learning', 'post'],
['orange', 'juice', 'is', 'the', 'liquid', 'extract', 'of', 'fruit'],
['orange', 'juice', 'comes', 'in', 'several', 'different', 'varieties'],
['this', 'is', 'the', 'last', 'machine', 'learning', 'book'],
['orange', 'juice', 'comes', 'in', 'several', 'different', 'packages'],
['orange', 'juice', 'is', 'liquid', 'extract', 'from', 'fruit', 'on', 'orange', 'tree']]
import numpy as np
def sent_vectorizer(sent, model):
sent_vec =[]
numw = 0
for w in sent:
try:
if numw == 0:
sent_vec = model[w]
else:
sent_vec = np.add(sent_vec, model[w])
numw+=1
except:
pass
return np.asarray(sent_vec) / numw
V=[]
for sentence in sentences:
V.append(sent_vectorizer(sentence, model))
X_train = V[0:6]
X_test = V[6:9]
Y_train = [0, 0, 0, 0, 1,1]
Y_test = [0,1,1]
from sklearn.neural_network import MLPClassifier
classifier = MLPClassifier(alpha = 0.7, max_iter=400)
classifier.fit(X_train, Y_train)
df_results = pd.DataFrame(data=np.zeros(shape=(1,3)), columns = ['classifier', 'train_score', 'test_score'] )
train_score = classifier.score(X_train, Y_train)
test_score = classifier.score(X_test, Y_test)
print (classifier.predict_proba(X_test))
print (classifier.predict(X_test))
df_results.loc[1,'classifier'] = "MLP"
df_results.loc[1,'train_score'] = train_score
df_results.loc[1,'test_score'] = test_score
print(df_results)
References
1. fasttext.cc
2. fastText
3. Classification with scikit learn
4. english-vectors
5. How to use pre-trained word vectors from Facebook’s fastText
6. What is the main difference between word2vec and fastText?