Text search box can be found almost in every web based application that has text data. We use search feature when we are looking for customer data, jobs descriptions, book reviews or some other information. Simple keyword matching can be enough in some small tasks. However when we have many results something better than keyword match would be very helpful. Instead of going through a lot of results we would get results grouped by topic with a nice summary of topics. It would allow to see information at first sight.
In this post we will look in some machine learning algorithms, applications and frameworks that can analyze output of search function and provide useful additional information for search results.
Machine Learning Clustering for Search Results
Search results clustering problem is defined as an automatic, on-line grouping of similar documents in a search results list returned from a search engine. [1] Carrot2 is the tool that was built to solve this problem.
Carrot2 is Open Source Framework for building Search Results Clustering Engine. This tool can do search, cluster and visualize clusters. Which is very cool. I was not able to find similar like this tool in the range of open source projects. If you are aware of such tool, please suggest in the comment box.
Below are screenshots of clustering search results from Carrot2
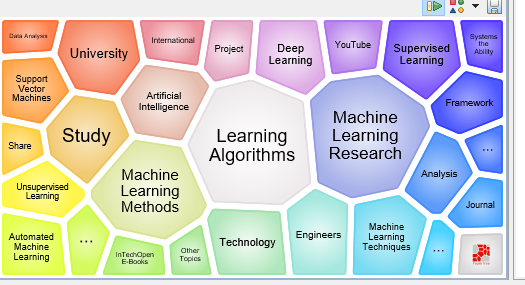
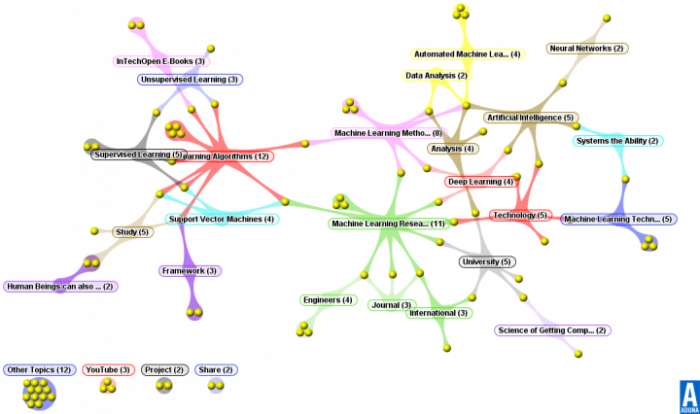
The following algorithms are behind Carrot2 tool:
Lingo algorithm constructs a “term-document matrix” where each snippet gets a column, each word a row and the values are the frequency of that word in that snippet. It then applies a matrix factorization called singular value decomposition or SVD. [3]
Suffix Tree Clustering (STC) uses the generalised suffix tree data structure, to efficiently build a list of the most frequently used phrases in the snippets from the search results. [3]
Topic modelling
Topic modelling is another approach that is used to identify which topic is discussed in documents or text snippets provided by search function. There are several methods like LSA, pLSA, LDA [11]
Comprehensive overview of Topic Modeling and its associated techniques is described in [12]
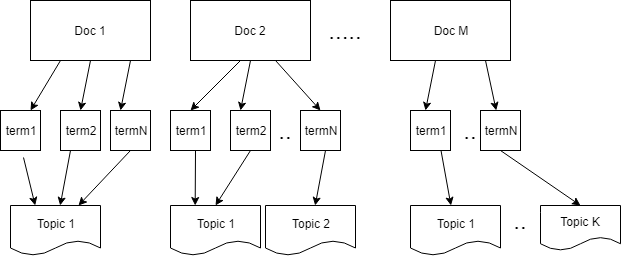
Topic modeling can be represented via below diagram. Our goal is identify topics given documents with the words
Below is plate notation of LDA model.
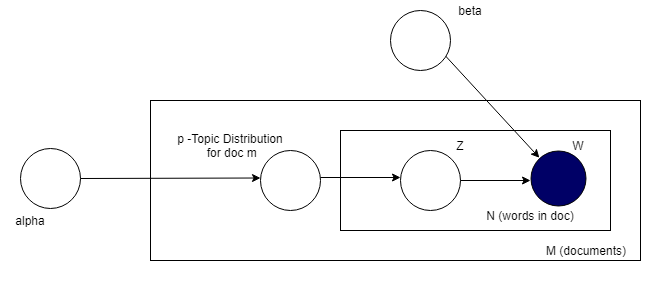
Plate notation representing the LDA model. [19]
αlpha is the parameter of the Dirichlet prior on the per-document topic distributions,
βeta is the parameter of the Dirichlet prior on the per-topic word distribution,
p is the topic distribution for document m,
Z is the topic for the n-th word in document m, and
W is the specific word.
We can use different NLP libraries (NLTK, spaCY, gensim, textacy) for topic modeling.
Here is the example of topic modeling with textacy python library:
Topic Modeling Python and Textacy Example
Here are examples of topic modeling with gensim library:
Topic Extraction from Blog Posts with LSI , LDA and Python
Data Visualization – Visualizing an LDA Model using Python
Using Word Embeddings
Word embeddings like gensim, word2vec, glove showed very good results in NLP and are widely used now. This is also used for search results clustering. The first step would be create model for example gensim. In the next step text data are converted to vector representation. Words embedding improve preformance by leveraging information on how words are semantically correlated to each other [7][10]
Neural Topic Model (NTM) and Other Approaches
Below are some other approaches that can be used for topic modeling for search results organizing.
Neural topic modeling – combines a neural network with a latent topic model. [14]
Topic modeling with Deep Belief Nets is described in [17]. The concept of the method is to load bag-of-words (BOW) and produce a strong latent representation that will then be used for a content based recommender system. The authors report that model outperform LDA, Replicated Softmax, and DocNADE models on document retrieval and document classification tasks.
Thus we looked at different techniques for search results clustering. In the future posts we will implement some of them. What machine learning methods do you use for presenting search results? I would love to hear.
References
1. Lingo Search Results Clustering Algorithm
2. Carrot2 Algorithms
3. Carrot2
4. Apache SOLR and Carrot2 integration strategies
5. Topical Clustering of Search Results
6. K-means clustering for text dataset
7. Document Clustering using Doc2Vec/word2vec
8 Automatic Topic Clustering Using Doc2Vec
9. Search Results Clustering Algorithm
10. LDA2vec: Word Embeddings in Topic Models
11. Topic Modelling in Python with NLTK and Gensim
12. Topic Modeling with LSA, PLSA, LDA & lda2Vec
13. Text Summarization with Amazon Reviews
14. A Hybrid Neural Network-Latent Topic Model
15. docluster
16. Deep Belief Nets for Topic Modeling
17. Modeling Documents with a Deep Boltzmann Machine
18. Beginners guide to topic modeling in python
19. Latent Dirichlet allocation