In this post we explore machine learning text classification of 3 text datasets using CNN Convolutional Neural Network in Keras and python. As reported on papers and blogs over the web, convolutional neural networks give good results in text classification.
Datasets
We will use the following datasets:
1. 20 newsgroups text dataset that is available from scikit learn here.
2. Dataset of web pages. The web documents are downloaded manually from web and belong to two categories : text mining or hidden markov models (HMM). This is small dataset that consists only of 20 pages for text mining and 11 pages for HMM group.
3. Datasets of tweets about Year Resolutions, obtained from data.world/crowdflower here.
Convolutional Neural Network Architecture
Our CNN will be based on Richard Liao code from [1], [2]. We use convolutional neural network that is built with different layers such as Embedding , Conv1D, Flatten, Dense. For embedding we utilize pretrained glove dataset that can be downloaded from web.
The data flow diagram with layers used is shown below.
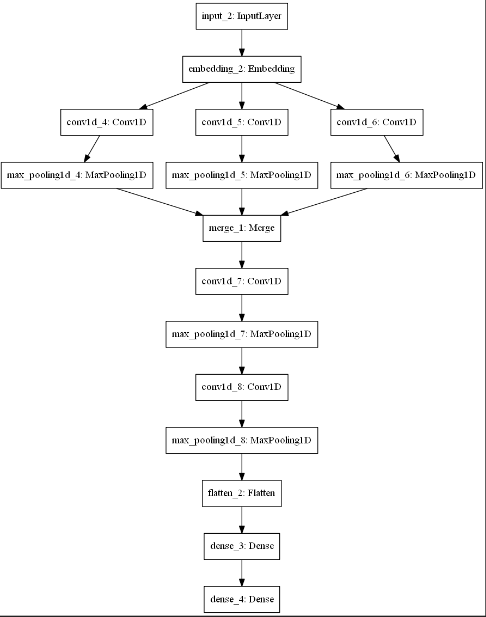
Here is the code for obtaining convolutional neural net diagram like this. Insert it after model.fit (…) line. It requires installation of pydot and graphviz however.
model.fit(.....) import pydot pydot.find_graphviz = lambda: True print (pydot.find_graphviz()) import os os.environ["PATH"] += os.pathsep + "C:\\Program Files (x86)\\Graphviz2.38\\bin" from keras.utils import plot_model plot_model(model, to_file='model.png')
1D Convolution
In our neural net convolution is performed in several 1 dimensional convolution layers (Conv1D)
1D convolution means that just 1-direction is used to calculate convolution.[3]
For example:
input = [1,1,1,1,1], filter = [0.25,0.5,0.25], output = [1,1,1,1,1]
output-shape is 1D array
We can also apply 1D convolution for 2D data matrix – as we use in text classification.
The good explanation of convolution in text can be found in [6]
Text Classifiction of 20 Newsgroups Text Dataset
For this dataset we use only 2 categories. The script is provided here The accuracy of network is 87%. Trained on 864 samples, validate on 215 samples.
Summary of run: loss: 0.6205 – acc: 0.6632 – val_loss: 0.5122 – val_acc: 0.8651
Document classification of Web Pages.
Here we use also 2 categories. Python script is provided here.
Web page were manually downloaded from web and saved locally in two folders, one for each category. The script is loading web page files from locale storage. Next is preprocessing step to remove web tags but keep text content. Here is the function for this:
def get_only_text_from_html_doc(page):
"""
return the title and the text of the article
"""
soup = BeautifulSoup(page, "lxml")
text = ' '.join(map(lambda p: p.text, soup.find_all('p')))
return soup.title.text + " " + text
Accuracy on this dataset was 100% but was not consistent. In some other runs the result was only 83%.
Trained on 25 samples, validate on 6 samples.
Summary of run – loss: 0.0096 – acc: 1.0000 – val_loss: 0.0870 – val_acc: 1.0000
Text Classification of Tweet Dataset
The script is provided here.
Here is the accuracy was 93%. Trained on 4010 samples, validate on 1002 samples.
Summary of run – loss: 0.0193 – acc: 0.9958 – val_loss: 0.6690 – val_acc: 0.9281.
Conclusion
We learned how to do text classification for 3 different types of text datasets (Newsgroups, tweets, web documents). For text classification we used Convolutional Neural Network python and on all 3 datasets we got good performance on accuracy.
References
1. Text Classification, Part I – Convolutional Networks
2. textClassifierConv
3. What do you mean by 1D, 2D and 3D Convolutions in CNN?
4.How to implement Sentiment Analysis using word embedding and Convolutional Neural Networks on Keras.
5. Understanding Convolutional Neural Networks for NLP
6. Understanding Convolutions in Text
7. Recurrent Neural Networks I